近年来,AI的进化让人目不暇接。从GPT系列“读懂语言”,到Sora系列“看世界”,我们一次次被AI惊人的能力所震撼。但一个更深刻的问题随之而来:如果AI要真正走进物理世界,成为能洗衣、做饭、装配的机器人,它需要什么?
波士顿动力的机器人可以后空翻,北京人形机器人创新中心(以下简称“北京人形”)的“具身天工Ultra”也能跑完半程马拉松。这些“体能”上的飞跃肉眼可见。然而,让机器人完成一个后空翻很难,但让它“理解”面前的水杯为什么倒下后水会洒出来,或许更难。这,就是具身智能面临的“物理鸿沟”。
近日,“北京人形”开源了其全新的具身世界模型——WoW(World-Omniscient World Model)。“WoW就是为了让机器人‘理解物理世界’,并且给到算法触摸世界的双手。”北京人形相关技术人员说。
为什么“以假乱真”还不够?
Sora 2的出现,确实让AI成了个出色的“电影导演”,它拍出的“大片”逼真到让人惊叹。但在具身智能领域,一个机器人不能只当“观众”或“导演”,它还要当“物理学家”,因为“看起来真实”和“物理上正确”是两码事。
机器人需要的,是对“时序一致性”和“物理因果链”的统一。比如一个东西被推了,它应该往哪儿倒;一个杯子倒了,水必须洒出来。Sora 2或许能生成一个“看起来”很酷的机器人动作,但WoW要确保这个动作符合牛顿的规矩。
“相较于Sora 2,WoW具身世界模型在模拟机器人操作的时空一致性、物理推理能力表现更为出色。”北京人形相关技术人员表示。
在素材的对比测试中,无论是让模型模拟“依次抓取火方块、柔性方块、水方块”,还是“打开一本图书”,WoW生成的模拟结果在物理交互的准确性上,都显现出优势。
这种差异的背后,源于WoW不同的构建思路。它不是一个单纯的视频生成器,而是一个被设计为“物理引擎+想象系统”的DiT(Diffusion Transformer)世界生成基座模型。它的核心任务是根据环境状态与历史帧,预测未来场景、推演物理演化,并还原动态的因果链。要实现这一点,数据是关键。WoW的学习材料并非来自互联网上的海量视频,而是来自一个更专注的数据库。“北京人形”相关技术人员表示,他们从800万条海量的“机器人与物理世界交互轨迹”中,通过自建的数据优化精炼管线,筛选出了200万条高质量的训练集。这种“交互数据”而非“观察数据”,可能是WoW理解物理的关键。
此外,该团队还验证了模型规模与性能的“幂律增长”关系。他们训练了从1.3B(“B”代表十亿)、2B、7B到14B参数的全系列模型。研究结果证明:“随着模型规模提升,物理一致性与生成稳定性以及泛化性呈显著上升趋势。”
如何让模型“自己教自己”?
如果说庞大且高质量的交互数据是“教材”,那么WoW的核心创新之一,就是一套名为SOPHIA(Solver-Critic-Refiner)的“自学方法”。“北京人形”在其研究中称,这是“业内首次提出SOPHIA框架,让世界模型‘自己教自己’。”
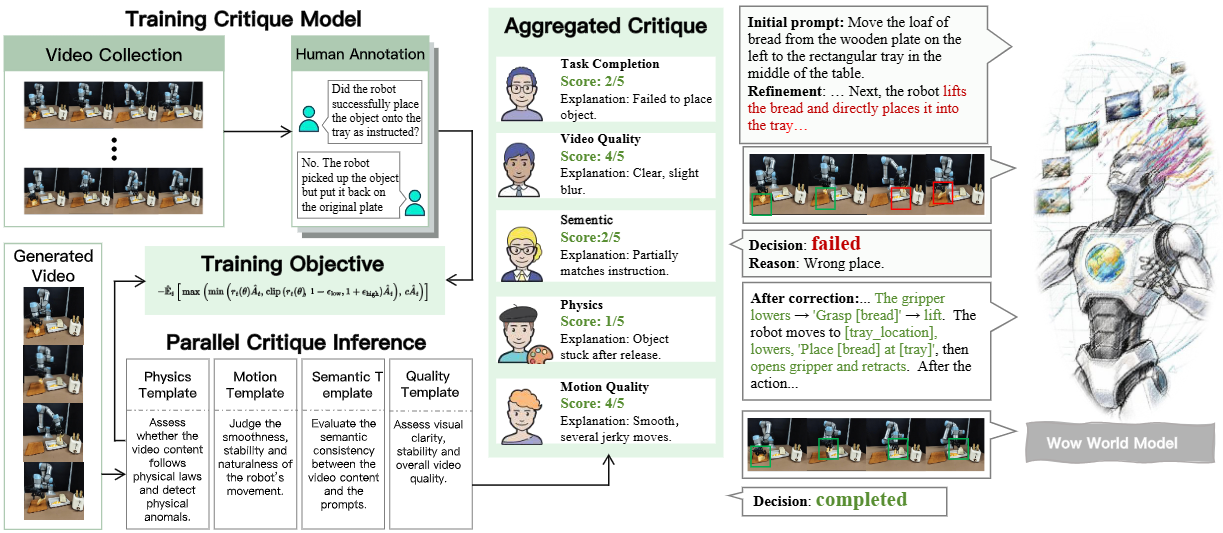
▲左侧展示了动态评论模型,它通过真实与合成视频的标注训练,学会判断生成画面的物理合理性。右侧展示优化智能体,根据评论模型的反馈不断改写提示词、重新生成视频,形成一个“生成-批评-改进”的闭环优化过程
这套机制,试图模拟人类“想象-验证-修正-再想象”的核心智能特征。它由两个关键部分组成,形成了一个“生成-批评-改进”的闭环优化过程。
但光会“想”还不行,机器人必须能“做”。WoW系统的另一大支柱,是FM-IDM逆动力学模型(Flow-Mask Inverse Dynamics)。这正是那双“触摸世界的双手”。它的作用,是将在“想象”中生成的视频翻译成真实世界中可执行的机器人指令。通过给定连续两帧预测视频,FM-IDM能够计算出机器人末端执行器的动作变化量,类似AI在脑子里想好了“手从A点移动到B点”的画面,FM-IDM就能反推出“机械臂关节需要旋转X度、Y度”的具体指令。技术人员解释说,“这标志着真正实现从生成到执行的跨越。”
开源一个“具身大脑”意味着什么?
一个模型是否真正理解了规律,最好的检验标准是“泛化能力”。“WoW不是在记忆训练场景,而是在学习‘物理规律的抽象本质’。”“北京人形”在报告中强调,模型具备“跨机器人形态泛化、任务泛化、场景泛化全方位能力”。
“北京人形”相关技术人员表示,WoW的泛化能力体现在多个层面。在“域内”,它可以生成长程、复杂的任务视频,例如“打开洗碗机”,乃至“依次按下红色按钮,收拾餐具,按下绿色开关”这样的多步任务。在“域外”,它能将其学到的知识,应用到未曾见过的机器人本体和场景上。例如,生成“具身天工2.0”机器人(未用于训练)执行“把橙子放进盘子里”“倒酒”等任务的视频。
“我们希望WoW能成为世界模型的研究基础设施。”“北京人形”技术人员展望道。在他们看来,WoW一方面可以实现“自我造数”(AI拥有“自我造数”能力),解决数据稀缺问题;另一方面,它打通了“从视觉‘想象’中反推真实可执行的动作指令”的通路,使机器人在抓取、装配等任务上的自主能力有望大幅提升。
“WoW通过系统性结合完成了‘想象世界→理解物理→生成视频→执行动作→再学习’的逻辑闭环。”“北京人形”技术人员说。此前,该中心已经展示了其在“能跑”和“好用”方面的实力,而WoW的开源,则补全了“大脑”层面的关键拼图。通过此次研究,也相信北京人形机器人将持续开源开放,助力行业打造最能跑最好用的具身智能机器人。或许在不远的将来,AI不再只是“模拟人”,而是与人类共同探索世界、建设世界的伙伴。
撰文:记者 段大卫
编辑:段大卫


 人民号
人民号 科普号
科普号 北京号
北京号 微博号
微博号 头条号
头条号 腾讯号
腾讯号 百度号
百度号 央视频号
央视频号 抖音号
抖音号 微信号
微信号


















